作者:(日)渡边康弘;金磊(译)
出版时间:2017年11月
阅读本书时,摘抄了书中具有指导意义的方法,并再文末做了适合自己的方法,指导后续阅读;
作者给出了阅读前的建议:
- 阅读之前不要看书的目录,避免被作者的编排让自己有了一个思维定式
- 阅读的思路:先通篇粗度-> 记录自己感兴趣的知识 -> 针对性的细读
共振阅读法中的5步共鸣
步骤0:接触书本,明确自己的目的。
步骤1:通过随意翻阅,让大脑“下载”信息。
步骤2:在三栏表格中绘制曲线。
步骤3:从曲线中感兴趣的那一页上摘出单词。
步骤4:凭着感兴趣的单词,带着问题去阅读。
步骤5:基于从这本书中所获得的想法,制订出行动计划
(根据以上步骤我的理解:通过绘制曲线发现自己对书中哪些部分感兴趣,然后挑选关键词进行细度,如果觉得内容引人入胜无需考虑必须在规定时间读完,继续深度即可;完成全书粗度后,需要制定计划和写出你的心得及想法,便于回顾)
进入到“共振阅读”的准备阶段“步骤0”。先从“记下书名”开始,依次按顺序在①~⑥的位置上记录信息:
①写下阅读的目的
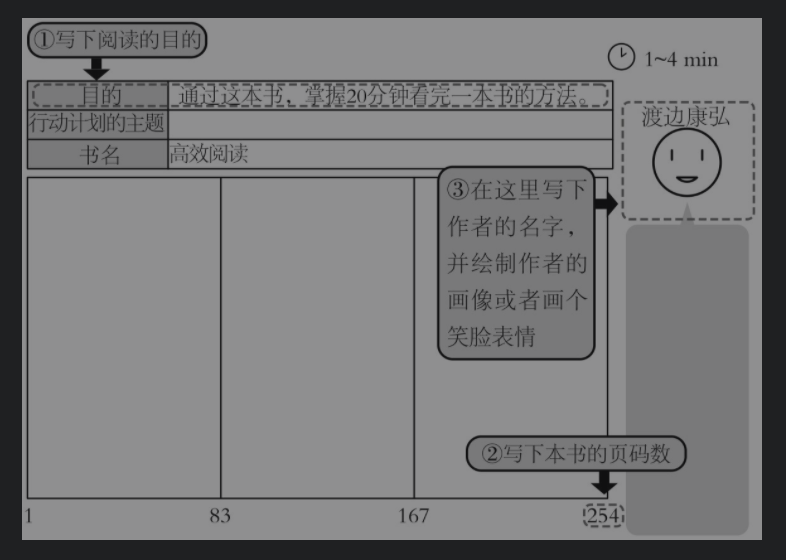
②写下页数
③写下作者的名字、绘制出画像或者画个“笑脸”的表情
④随意翻阅,对书中内容进行大致浏览
⑤将从作者那里接收到的信息,简短地写下来
⑥作者为什么必须写作这本书?
写作的建议:
①首先尝试直接“放松”地打草稿
②在撰写书评时,要设想一个读者对象
③“放松”地进行整理
④在文章中加入我们自己的风格特点,并尝试大声朗读出来
制定行动计划:
①看着“共振地图”,寻找与“人”或“事”有关的提示
②从书中的语句联想到提示
③将行动计划记到日程表中
④将计划付诸行动
参加读书会、学习会的三个好处:
·能结识志同道合的朋友。
·能从他人那里了解到与自己不同的观点。
·交流分享我们所学到的东西。
拓展自己专业领域的方法:
1.思考拓展自己专业领域的目的
2.去大型书店逛逛
3.购买8本关于该专业领域的书籍,以及2本非该专业领域的书籍
通过“共振阅读”掌握专业性知识的步骤
①设定阅读的目的。
②将所有的书籍拍到一张照片中。
③随意翻阅所有的书籍,然后休息。
④找出“共振词汇”。
⑤从书中找出与之关联的内容。
⑥用自己的话进行总结。
⑦想出自己的“关键词”。
⑧利用这些“关键词”找到新的切入口(意见)。
⑨基于新的切入口,撰写报告或笔记。
3年后的你
Who(谁)和谁在一起?
Where(场合)在什么样的场合?
When(时间)3年后的几月几日?
What(做的事情)在做什么?
Why(原因)为什么要做那件事?
How(方法)怎样做才能实现?
看完本书,我反思了自己及获得的一些感悟:
。去研究其他的粗度方法,找到适合自己的方式
。分享自己读书的经历,以前不知道怎么读书?就是按许三多似的方法(从A看到Z);现在知道带着问题去看书,而且问题需要明确在脑子中反复浮现多遍、最好是在纸上写下来,方便最后回头过来分析
。读书在于形成理论,优化自己的思维体系,指导自己今后的行动;所以,重在最后的行动
。整理细自己的读书路径,使用钢笔将阅读的精髓记录,便于记忆(没有条件,可以使用网络读书笔记)
1.写下书名、作者、国家、年代、背景(加深记忆,了解本书创作环境)2.提出多个问题(我需要从书中获得哪些知识)3.按书中的共振阅读法找出关键点: a.找出感兴趣的章节、页数 b.根据第一次的筛选,找出感兴趣的词汇 c.对关键词汇进行扩展阅读;钢笔或者网络笔记记录感兴趣的句子或思想 d.找到前面提出问题的答案4.完成全书阅读后,参考书的目录,写出自己的感想及心得;分析与提出问题时的对比,得出总结性的心得;确定该书是否需要细读5.总结所获得的帮助,结合自己的人生、经历
总之,阅读的目的是为了与作者对话,达到与之沟通及思想的碰撞;你可以想象一下作者就坐在你身边,与你平等的进行交流,探讨书中的观点与实例;你可以提出自己的见解,在书中寻找答案,形成自己的思维体系,指导我们更好的生活及工作。
]]>